
ChatGPTやMidjourneyをはじめとする生成AIツールを業務に取り入れる企業が急増している一方で、「これって著作権侵害にならないの?」という不安を抱えている方は多いのではないでしょうか。

SNSに投稿した画像が有名イラストレーターの作風に似ていると炎上したり、文章生成AIで作った記事が既存メディアのコンテンツに酷似していると指摘されたりと、実際にトラブルへ発展したケースも報告されています。
この記事では、生成AI利用が著作権侵害になる境界線、日本における法律や規制の全体マップ、そして実際に問題になった具体例を網羅的に解説します。
開発・学習段階と生成・利用段階の違い、類似性と依拠性の判断基準、企業が講じるべき実践的な対策、さらに利用規約のチェックポイントや文化庁ガイドラインの読み解き方まで、実務で迷わないための判断軸を提供します。

生成AIが著作権侵害になる境界線を正確に理解する
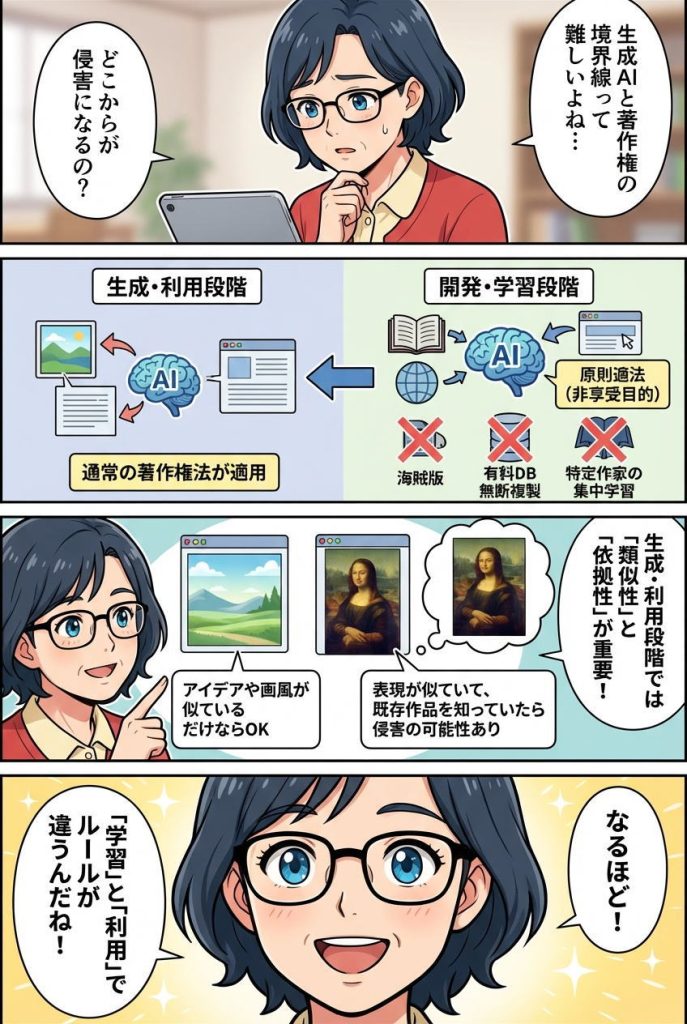
生成AIと著作権の問題を語るとき、最初に押さえるべきポイントは「AIの開発・学習段階」と「生成・利用段階」では適用されるルールが全く異なるという点です。混同すると判断を誤るため、それぞれの段階で何が許され、何が禁じられているのかを明確に理解しましょう。
開発・学習段階は原則として適法だが例外がある
日本の著作権法第30条の4では、著作物に表現された思想や感情を享受する目的でない利用、つまり情報解析や技術開発のための利用であれば、原則として著作権者の許諾なく著作物を利用できると定められています。
AIの開発企業がウェブ上の膨大なテキストや画像を収集して学習データセットを構築する行為は、この非享受目的利用に該当するため、基本的には適法です。人間が小説を読んで感動したり絵画を鑑賞して楽しんだりする行為とは本質的に異なり、AIはデータのパターンや統計的特徴を抽出しているだけだからです。
ただし、無制限に許されるわけではありません。以下のケースでは例外的に違法と判断される可能性があります。
- 有料で販売されている学習用データベースを購入せず無断で複製して利用する行為
- 海賊版サイトと知りながら、そこから著作物を収集して学習に使用する行為
- 特定のクリエイターの作品のみを集中的に学習させ、その作家の表現をそのまま出力させることを意図した学習
つまり、本来クリエイターが得られるはずの正当な利益を奪う悪質な行為は、学習目的であっても認められないのです。
生成・利用段階では通常の著作権法が適用される
AIが画像や文章を生成し、それをSNSに投稿したり製品デザインとして利用したりする段階では、AIを使わない通常の創作活動と同様に著作権法が適用されます。つまり、AI生成物が既存の著作物と類似しており、かつ依拠している場合は著作権侵害となる可能性があります。
ここで重要なのが「類似性」と「依拠性」という2つの判断要素です。
類似性とは、生成物が既存の著作物の表現上の本質的な特徴を直接感じ取れるほど似ていることを指します。単にアイデアやテーマ、画風が似ているだけでは原則として著作権侵害にはなりません。著作権法が保護するのは具体的な「表現」であり、アイデアそのものは保護の対象外だからです。
依拠性とは、既存の著作物を知った上で、それを元にして新しい作品を作ったことを指します。偶然の一致であれば著作権侵害にはなりません。ただし、AI利用者が既存作品を知らなかったとしても、AIの学習データにその作品が含まれていた場合、依拠性があったと推認される可能性があります。
文化庁の見解でも、AIが学習データに含まれる著作物を通じて生成物を作り出す以上、利用者が知らなくても依拠性が認められるリスクがあると整理されています。つまり、意図せずとも侵害が成立する可能性があるため、企業は生成物のチェック体制を整備する必要があります。
侵害になるかどうかの判断フロー
実務で迷わないために、以下のフローで判断するとよいでしょう。
- 生成物が既存の著作物と表現上の本質的な特徴が似ているか(類似性)
- 既存の著作物を知っていたか、またはAIの学習データに含まれていたか(依拠性)
- 私的使用など権利が制限される場合に該当しないか
類似性と依拠性の両方が認められ、かつ権利制限規定に該当しない場合、著作権侵害が成立する可能性が高まります。商用利用であれば私的使用には該当しないため、特に慎重な判断が求められます。
著作権法第30条の4を正しく理解する

生成AIと著作権を語る上で最重要となる条文が、著作権法第30条の4です。この規定を正確に理解することが、AI活用における法的リスク管理の第一歩となります。
条文の構造と非享受目的利用の考え方
著作権法第30条の4は、「著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合」には、必要と認められる限度で著作物を自由に利用できると定めています。
享受とは、著作物の視聴などを通じて知的・精神的欲求を満たすことを意味します。文章なら読むこと、音楽や映画なら鑑賞すること、プログラムなら実行することが享受に該当します。
AIの学習は、作品を楽しむのではなくデータのパターンを統計的に解析する行為であるため、享受目的には該当しません。そのため原則として著作権者の許諾なく学習データとして利用できるのです。
適用される具体的な場面
第30条の4が適用される場面として、以下のケースが挙げられます。
- AI学習用データセット構築のために著作物を含むデータを収集・加工する場合
- 作成した学習用データセットを学習プログラムに入力する際に著作物を複製する場合
- 基盤モデル作成に向けた事前学習のために著作物を複製する場合
- 既存の学習済みモデルに対する追加学習のために著作物を複製する場合
これらは情報解析という非享受目的での利用であるため、著作権法第30条の4により適法とされています。
但し書きの例外|権利者の利益を不当に害する場合
ただし条文には但し書きがあり、「著作権者の利益を不当に害することとなる場合」は例外的に違法となります。文化庁の見解では、以下のようなケースが例外に該当するとされています。
- 有償で提供されているデータベース著作物をAI学習のために無許諾で複製する場合
- 情報解析用に将来販売されると推認されるデータベースを無許諾で複製する場合
- 海賊版サイトなど違法にアップロードされた著作物をAI学習に利用する場合
これらは、本来著作権者が得られるはずのライセンス市場での利益を奪う行為であり、不当に権利者の利益を害するため違法と判断されます。
享受目的が併存する場合の取り扱い
非享受目的と享受目的が併存する利用、つまり情報解析が主目的であっても作品を鑑賞する目的も含まれている場合は、第30条の4の適用は受けられません。
たとえば、特定のクリエイターの作品のみを集中的に学習させ、その創作的表現の全部または一部を出力させることを目的とした学習は、享受目的が併存すると判断される可能性があります。このような場合は著作権者の許諾が必要です。
AI生成物の著作権は誰のものになるのか
生成AIで作ったコンテンツの著作権が誰に帰属するのかは、ビジネス活用において極めて重要な問題です。
自社の資産として保護できるのか、それとも誰でも自由に使える状態なのかを理解しましょう。
原則|AIが自律的に生成したものに著作権はない
日本の著作権法は、著作物を「思想又は感情を創作的に表現したもの」と定義しており、この主体は「人」であると解釈されています。そのため、AIが自律的に生成しただけのものには原則として著作権は発生しません。
単純なプロンプト入力でAIが自動出力した文章や画像は、人間の思想や感情が創作的に表現されたとは言えないため、著作物として保護されないのです。つまり、特定の権利者がいないパブリックドメインに近い状態となります。
例外|人間の創作的寄与があれば著作物になる
ただし、AIを単なる「道具」として利用し、そこに人間による創造的な貢献が認められる場合は、例外的にその生成物が「人間の著作物」として保護される可能性があります。
文化庁の見解では、人間に「創作意図」があり、創作の過程で具体的な指示を出すといった「創作的寄与」が認められれば、その人が著作者になるとされています。
創作的寄与が認められやすい例としては、以下のようなケースが挙げられます。
- プロンプトを何度も具体的に修正し、意図する表現に近づけるための試行錯誤を繰り返す
- 生成した画像に対して「尻尾を長くして」「背景色を変えて」といった具体的な修正指示を何度も出す
- AI生成物を基にPhotoshopなど別ツールで大幅に加筆・修正を加えて一つの作品に仕上げる
- 複数の生成物を組み合わせ、構成や配置において人間の選択と編集が加わる
逆に、「かわいい猫のイラスト」のような単純で短い指示で生成を終え、そのまま利用するケースでは、創作的寄与が認められにくいでしょう。
利用規約による権利帰属の違い
AI生成物の著作権が誰に帰属するかは、利用するサービスの利用規約によっても異なります。
- ユーザーに帰属する:Adobe Firefly、DALL-E 3など多くの商用サービス
- サービス提供者に帰属する:一部の無料サービスや試験版
- 共有される:生成物をサービス側も利用できる権利を保持するケース
商用利用を検討する場合は、必ず利用規約で権利帰属を確認しましょう。生成物をビジネスで活用するには、ユーザーに著作権が帰属するサービスを選ぶことが基本です。
類似性と依拠性の判断基準を詳しく理解する
著作権侵害が成立するかどうかは、類似性と依拠性という2つの要件で判断されます。これらの判断基準を正確に理解することが、リスク管理の核心となります。
類似性の判断|表現上の本質的な特徴の共通性
類似性とは、AI生成物と既存の著作物との間で、表現上の本質的な特徴が共通していることを指します。裁判実務では、「既存著作物の本質的な特徴を直接感得できるか」が判断基準とされています。
重要なのは、アイデアや作風が似ているだけでは類似性は認められないという点です。著作権法はアイデアや思想そのものを保護しないため、「魔法少女が活躍する物語」「未来都市を描いた絵」といった抽象的な設定やテーマの共通性だけでは侵害になりません。
一方で、キャラクターの具体的な服装デザイン、物語の展開における創作的な表現、絵画における構図や色彩の独自の組み合わせなど、創作的な表現が共通している場合には類似性が認められます。
判断のポイントとしては以下が挙げられます。
- 創作的表現において細部まで一致または酷似しているか
- 既存作品の個性的な特徴がAI生成物から感じ取れるか
- ありふれた表現の範囲を超えた独自性が共通しているか
依拠性の判断|既存著作物へのアクセスと利用
依拠性とは、既存の著作物に接して、それを自分の作品制作に用いたことを意味します。偶然の一致であれば依拠性がなく、著作権侵害は成立しません。
従来の創作活動では、制作者が既存著作物を実際に見たり読んだりしていたかが争点となりました。しかしAI生成物の場合、この判断が複雑になります。
文化庁の見解では、依拠性について以下のように整理されています。
AI利用者が既存の著作物を認識していた場合
利用者が既存作品を参考にした上でAI生成物を生成しているため、既存著作物に依拠していると考えられます。たとえば、過去に見たイラストを思い出して、それに似せようとプロンプトを工夫した場合などです。
AI利用者は既存著作物を認識していないが、AI学習データに含まれる場合
このケースが最も議論を呼んでいます。客観的に既存著作物へのアクセスがあったと認められるため、依拠性が推認される可能性があります。ただし、AIの開発段階で既存著作物の創作的表現が出力されないような技術的措置がとられている場合は、依拠性がないと判断される余地もあります。
また、利用者のプロンプト内容やフィードバックによる修正回数などの創作的寄与、原著作物の要素を除外する積極的な指示などによって、依拠性の推認を妨げることも考えられます。
AI利用者が既存著作物を認識しておらず、かつAI学習データにも含まれない場合
このケースでは、AI生成物が既存著作物と類似していても偶然の一致とみなされ、依拠性は認められません。
裁判所が重視する判断要素
過去の裁判例では、依拠性の判断において以下のポイントが総合的に考慮されています。
- 後発作品の制作者が、制作時に既存著作物の表現内容を知っていたか(接する機会があったか、周知・著名だったか)
- 後発作品と既存著作物との同一性の程度(経験則上、依拠していない限りこれほど類似することはないといえる程の顕著な類似性)
- 後発作品の制作経緯(既存著作物に依拠せず専ら独自創作した経緯を合理的に説明できるか、制作の時系列)
AI生成物においても、これらの要素を意識してプロンプトや生成過程を記録しておくことが、万が一の紛争時に依拠性を否定する材料となります。
著作権侵害の実例から学ぶリスクの具体像
実際に発生した事例を知ることで、どのような利用が問題となるのか、どこに注意すべきかが明確になります。国内外の代表的な事例を見ていきましょう。
海外の訴訟事例|大手企業による集団訴訟
ニューヨーク・タイムズ対OpenAI・Microsoft
大手新聞社ニューヨーク・タイムズは、自社の記事数百万件を無断で学習データに利用され著作権を侵害されたとして、ChatGPTの開発元OpenAIとマイクロソフトを提訴しました。
原告側は、両社が記事を学習した結果、読者との関係性が損なわれ購読料や広告による利益を侵害されたと主張しています。この訴訟は現在も係争中ですが、AI学習における報道機関のコンテンツ利用が争点となっています。
Getty Images対Stability AI
世界最大級のストックフォトサービスGetty Imagesは、画像生成AI「Stable Diffusion」の開発元を提訴しました。自社が権利を持つ1200万点以上の画像を許可なく学習データに利用されたと主張しています。
ただし米国の裁判所は、「モデルの訓練で著作物を保存・複製しておらず著作権法に違反していない」との判決を下し、Getty Images側の主張を退けました。
音楽業界の訴訟と和解
大手音楽レーベル3社(ユニバーサルミュージックなど)は、音楽生成AI「Suno」と「Udio」を著作権侵害で提訴しました。自社が権利を持つ楽曲が無断で学習データに使われたと主張していました。
その後、ユニバーサルミュージックはUdioと、ワーナー・ミュージック・スタジオは両社と提携を結び、AI学習に楽曲を使うことを認める代わりに対価を得ることで和解しています。和解に伴い、生成楽曲のダウンロード制限やプラットフォーム外への持ち出し禁止などの利用規約が変更されました。
日本国内の問題事例
海上保安庁のAIイラスト問題
2024年、海上保安庁が公開したパンフレットに使用されたAI生成イラストが、特定のイラストレーターの画風に酷似しているとSNS上で大きな批判を浴びました。結果としてパンフレットの公開が中止される事態に発展しています。
法的に著作権侵害と認定されたわけではありませんが、社会的な批判により組織の評判を大きく損なうリスクがあることを示す重要な事例です。特に公的機関や大企業では、法的に問題がなくても倫理的・社会的な観点から批判を受ける可能性があります。
AIグラビア写真集の販売停止問題
実在のアイドルの画像を無断で学習させたとされるAIを使い、生成された写真集が出版され大きな問題となりました。このケースは著作権だけでなく、モデルとなった人物の肖像権やパブリシティ権を侵害する可能性が極めて高く、多くの書店が販売を見合わせる事態となりました。
実在人物の顔や容姿を無断で商業利用することは、たとえAI生成であっても人格権の侵害となるリスクが高いことを示しています。
中国でのウルトラマン類似画像事件
2024年8月、中国の裁判所はある生成AIサービス会社に対し、「ウルトラマン」に酷似した画像を生成させたとして著作権侵害を認める判決を下しました。損害賠償額は10,000元(約20万円)で、ウルトラマンに類似した画像が生成されないようにする措置を求めました。
本判決では、「ウルトラマンを生成」といったキャラクター名を含むプロンプトを入力すると酷似した画像が生成される点が問題視されました。日本でも同様のリスクがあるため、特定のキャラクター名を指定した生成は避けるべきです。
YouTubeデータの無断利用問題
AppleやNvidiaなどの企業が、YouTubeの動画トランスクリプトを無断でAIモデルの訓練データとして使用していたことが報じられました。約17万3000本の動画から字幕データを収集していました。
YouTubeの利用規約では自動化された手段によるコンテンツの収集を禁止しており、この行為は規約違反とされています。著作権法上の問題だけでなく、プラットフォームの利用規約違反として法的責任を問われるリスクもあることを示す事例です。
企業がとるべき包括的なリスク対策
生成AIを安全にビジネスで活用するためには、多層的なリスク管理体制の構築が不可欠です。以下の対策を段階的に導入しましょう。
対策1|学習データがクリーンなツールを選定する
AI開発元が「権利的にクリーンなデータを使っている」と公表しているかを確認しましょう。学習データの出所が不透明なツールは、生成物に侵害リスクが潜む可能性があります。
推奨されるツールの特徴は以下のとおりです。
- Adobe Firefly:Adobe Stockや著作権フリー素材のみを使用し、学習データの透明性が高い
- Microsoft Copilot:著作権侵害の補償制度(Copilot Copyright Commitment)あり
- Google Gemini:学習データのポリシーを公開し、企業向けプランではデータの再学習オプトアウトが可能
- OpenAI(有料版):エンタープライズプランでは入力データが学習に使われない設定が可能
学習データの透明性、補償制度の有無、オプトアウト設定の可否を総合的に判断してツールを選定します。
対策2|社内ガイドラインと利用ルールを策定する
生成AIの利用目的、使用可能なツール、禁止事項を明文化し、全社員に周知徹底します。ガイドラインには以下の項目を盛り込むことが重要です。
基本方針
- 生成AIの概要と仕組み
- 著作権リスクの基礎知識
- 企業としての利用方針
利用ルール
- 利用可能なツールのリスト
- 特定の作家名・作品名・キャラクター名をプロンプトに含めない
- 機密情報や個人情報を入力しない
- 生成物を公開・商用利用する前に類似性チェックを実施する
記録保管
- プロンプトや生成ログを記録・保管する手順
- 生成過程の証拠を残す方法
承認プロセス
- 商用利用前の上長承認フロー
- リーガルチェックが必要なケースの基準
文化庁の資料やAI事業者ガイドラインを参考にしながら、自社の業態に合わせたガイドラインを策定しましょう。
対策3|プロンプト設計を工夫し依拠性を回避する
生成AIを使う際、プロンプトの設計が著作権リスクに直結します。特定の作家名、作品名、キャラクター名などの固有名詞をプロンプトに含めると、既存作品との類似性が高まり依拠性も認められやすくなります。
NGな指示例
- 「ピカソ風の絵を描いて」
- 「宮崎駿風のファンタジーイラスト」
- 「ポケモンのようなキャラクター」
- 「ジブリ風の背景」
推奨される指示例
- 「キュビズム風の抽象画、幾何学的な構図で」
- 「ファンタジックで温かみのあるアニメーション風、柔らかい線と淡い色彩で」
- 「丸みのあるかわいらしい生き物のキャラクター、大きな目と小さな体」
- 「緑豊かな森の風景、細密な自然描写で」
表現したい雰囲気を要素に分解して抽象的に指示することで、依拠性の推認を妨げることができます。
対策4|生成物は必ず人間が確認・編集する
AI生成物をそのまま完成品として利用するのは避け、必ず人間が内容を確認し加筆修正を加えましょう。これにより以下のメリットがあります。
- 既存著作物との類似性を人間の目でチェックできる
- 事実関係の誤り(ハルシネーション)を発見・修正できる
- 人間の創作的寄与が加わり、著作物として保護される可能性が高まる
- ブランド価値や品質を担保できる
GoogleやOpenAIなどの主要ベンダーも、最終的な生成物の確認は人間がおこなうことを推奨しており、AIに任せきりにしない姿勢が求められています。
対策5|類似性チェックツールを活用する
生成された成果物が既存の著作物と似ていないかを、Google画像検索や類似性チェックツールを用いて確認する手順を社内でマニュアル化しましょう。
画像の場合
- Google画像検索(画像をアップロードして類似画像を検索)
- TinEye(リバース画像検索)
- Pinterest Visual Search
テキストの場合
- CopyContentDetector(コピペチェックツール)
- Turnitin(学術論文向け類似性チェック)
- Google検索(特徴的なフレーズで検索)
特に商用利用の前にはこれらのツールで確認することを必須化し、チェック結果を記録として残しましょう。
対策6|定期的なリテラシー教育を実施する
従業員向けに生成AIと著作権に関する研修を定期的に実施し、最新の法的動向や判例を共有します。教育内容としては以下が推奨されます。
- 著作権の基礎知識(著作物とは、著作権侵害の要件など)
- 生成AIと著作権の関係(開発・学習段階と生成・利用段階の違い)
- 類似性・依拠性の判断基準
- 実際のトラブル事例と教訓
- 社内ガイドラインの理解度確認
文化庁が公表している「AIと著作権」の資料や、経済産業省のAI事業者ガイドラインを活用すると効果的です。定期的なアップデートと理解度テストを実施し、組織全体のリテラシー向上を図りましょう。
対策7|専門家によるリーガルチェックを受ける
商用利用や対外的に公開するコンテンツについては、弁護士や知的財産の専門家によるリーガルチェックを受けることで、見落としていたリスクを事前に発見できます。
特に以下のケースではリーガルチェックを必須としましょう。
- 大規模なマーケティングキャンペーンでの利用
- 製品パッケージや広告への使用
- メディア公開を伴うプレスリリース
- 継続的に使用するブランド資産の制作
専門家は最新の判例や法改正の動向を把握しているため、自社では気づかないリスクを指摘してもらえます。
対策8|補償制度のあるツールを優先的に選ぶ
万が一著作権侵害で訴えられた場合に備え、補償制度を提供しているAIツールを優先的に選定します。
主要ベンダーの補償制度は以下のとおりです。
- Microsoft:Copilot Copyright Commitmentにより法的責任を負担
- Adobe:Firefly利用者向けに補償プログラムを提供
- Google:企業向けプランで一定の補償あり
ただし補償が適用されるには条件があります。ベンダーが提供する安全機能を有効化していること、利用規約を順守していること、プロンプトに不適切な内容を含めていないことなどが求められます。補償制度はあくまで最終手段であり、日常的な運用では侵害を未然に防ぐ対策が最優先です。
利用規約の確認ポイントを押さえる
生成AIサービスを導入する際、利用規約の確認は必須です。見落としがちな重要ポイントを整理します。
商用利用の可否と制限事項
無料版と有料版で商用利用のルールが異なるケースが一般的です。以下を必ず確認しましょう。
- 商用利用が明示的に許可されているか
- 商用利用には特定のプランへのアップグレードが必要か
- 利用可能な範囲(広告、製品デザイン、出版など)に制限はあるか
- 生成物の販売や再配布は可能か
一部のサービスでは、個人利用は無料だが商用利用は有料プランが必須というケースもあります。契約プランと実際の利用目的が合致しているか確認が必要です。
生成物の権利帰属
生成されたコンテンツの著作権が誰に帰属するかを確認します。
- ユーザーに著作権が帰属するか
- サービス提供者が権利を保持するか
- 共有される(サービス側も利用できる権利を持つ)のか
商用利用を前提とする場合は、ユーザーに著作権が帰属するサービスを選ぶことが基本です。権利帰属が曖昧なサービスでは、後々トラブルになる可能性があります。
入力データの取り扱いとオプトアウト
ユーザーが入力したプロンプトやアップロードしたデータが、AIの再学習に利用されるかどうかを確認します。
- 入力データは学習に使われるか
- オプトアウト(学習に使わない設定)が可能か
- データの保存期間はどれくらいか
- データ削除の権利は保証されているか
機密情報や個人情報を含むデータを扱う場合は、オプトアウト設定が可能なエンタープライズプランを選択することが推奨されます。
免責事項と補償の範囲
著作権侵害などのトラブルが発生した場合、サービス提供者がどこまで責任を負うかを確認します。
- 生成物の利用により生じた紛争の責任は誰が負うか
- サービス提供者は一切の責任を免れる旨が記載されているか
- 補償制度はあるか、その適用条件は何か
多くのサービスでは「生成物の利用により生じた第三者との紛争については、利用者が自己の責任と費用で解決する」という免責条項があります。補償制度がある場合でも、適用には厳格な条件があるため詳細を把握しましょう。
禁止事項と違反時のペナルティ
サービス利用における禁止事項を確認します。
- 違法コンテンツの生成
- 特定個人の誹謗中傷や権利侵害
- 有害・差別的なコンテンツの生成
- 利用規約違反時のアカウント停止条件
違反した場合、アカウント停止や法的措置を取られる可能性があります。社内ガイドラインにも禁止事項を反映させましょう。
安全な利用のためのチェックリストを活用する
企業が生成AIを安全に利用するためには、段階ごとのチェック体制が重要です。文化庁の「AIと著作権に関するチェックリスト」を参考に、実務で使えるチェック項目を提示します。
導入前チェックリスト
□ 生成AIの仕組みと特性(学習データから類似物が生成される可能性)を理解しているか
□ 使用するAIの学習済みモデルに関する情報(学習データの出所、収集ポリシー)が提供されているか
□ 利用規約を確認し、著作権侵害の恐れがある利用方法の禁止・制限事項を把握したか
□ 商用利用が明示的に許可されているプランを選択しているか
□ 生成物の権利帰属がユーザーにあることを確認したか
□ 入力データの再学習オプトアウト設定が可能か確認したか
□ 著作権侵害時の補償制度の有無と適用条件を確認したか
□ 従業員などに対して適切な著作権教育を実施したか
□ 著作権侵害を生じさせない適正利用のための内部ルールを策定したか
□ 著作権侵害が生じた場合の対応手順を検討・整備したか
生成前チェックリスト
□ プロンプトに特定の作家名、作品名、キャラクター名を含めていないか
□ 固有名詞を避け、要素を抽象的に表現する指示になっているか
□ 既存の著作物をAIに入力する場合、権利者の許諾を得ているか
□ 入力する著作物と類似する生成物を生成させる目的(享受目的)ではないか
□ 機密情報や個人情報を入力していないか
□ 生成の目的と利用範囲が明確か(社内資料、SNS投稿、商用利用など)
生成後チェックリスト
□ Google画像検索などで既存著作物との類似性を確認したか
□ 特定の有名作品やキャラクターに似ていないか目視で確認したか
□ テキストの場合、特徴的なフレーズをGoogle検索して既存コンテンツとの重複を確認したか
□ 生成物に実在人物の顔や名前が含まれていないか確認したか
□ 人間による加筆・修正を加え、創作的寄与を付加したか
□ 事実関係の誤り(ハルシネーション)がないか確認したか
□ 生成過程(プロンプト、修正履歴、日時など)を記録・保管しているか
□ 既存の著作物を認識していなかったこと(依拠性がないこと)を説明できる状態にあるか
公開・商用利用前チェックリスト
□ 利用目的に応じた適切なプランを契約しているか
□ 社内の承認プロセスを経ているか
□ 必要に応じて専門家によるリーガルチェックを受けたか
□ 著作権表記が必要な場合、適切に表記しているか
□ AI生成物であることの開示が必要か確認したか(透明性の確保)
□ 公開後の監視体制(権利者からの指摘に対する対応フロー)が整っているか
このチェックリストを社内ツールとして整備し、生成AI利用の各段階で確認を徹底することで、著作権侵害のリスクを大幅に低減できます。
文化庁ガイドラインを正しく読み解く
文化庁が公表している「AIと著作権に関する考え方について」は、日本における生成AIと著作権の関係を理解する上で最も重要な公式見解です。このガイドラインの要点を実務に活かせる形で解説します。
ガイドラインの基本構造
文化庁のガイドラインは、AIと著作権の関係を「開発・学習段階(インプット)」と「生成・利用段階(アウトプット)」の2つのフェーズに明確に分けて整理しています。
それぞれのフェーズで適用される法律の条文や判断基準が異なるため、この区別を理解することが第一歩となります。
開発・学習段階に関する文化庁の見解
文化庁は、AI開発のための著作物利用について以下のように整理しています。
原則:非享受目的であれば適法
著作権法第30条の4により、著作物に表現された思想や感情を享受する目的でない場合(情報解析など)は、必要と認められる限度で著作物を自由に利用できます。AIの開発・学習は原則としてこれに該当するため適法です。
例外:享受目的が併存する場合は違法
ただし、以下のような場合は享受目的が併存すると判断され、著作権者の許諾が必要となります。
- 特定の作家の作品のみを学習させ、その創作的表現を出力させることを目的とする場合
- 既存の著作物と類似したものを生成させることを主目的とする学習
例外:権利者の利益を不当に害する場合は違法
学習目的であっても、以下は権利者の正当な利益を害するため違法です。
- 有償で提供されているデータベースを無断で学習に利用
- 海賊版サイトから著作物を収集して学習に利用
- 将来的に情報解析用として販売されると推認されるデータベースを無断利用
生成・利用段階に関する文化庁の見解
生成・利用段階では、通常の著作権法が適用されます。文化庁は以下のポイントを明示しています。
類似性と依拠性の両方が必要
AI生成物が著作権侵害となるには、既存著作物との「類似性」と「依拠性」の両方が認められる必要があります。
AI特有の依拠性の考え方
AI生成物における依拠性については、以下のように整理されています。
- 利用者が既存著作物を知っていた場合:依拠性あり
- 利用者は知らないがAI学習データに含まれる場合:依拠性が推認される可能性あり
- 利用者も知らずAI学習データにも含まれない場合:依拠性なし(偶然の一致)
創作的寄与があれば著作物になる
AI生成物に人間の「創作意図」と「創作的寄与」が認められれば、その人が著作者となり著作権が発生する可能性があります。単純なプロンプト入力だけでは創作的寄与は認められにくいですが、試行錯誤や大幅な修正を加えた場合は認められやすくなります。
ガイドラインが示す企業の対応指針
文化庁のガイドラインでは、企業が取るべき対応として以下を推奨しています。
- 生成AIの仕組みと著作権リスクを正しく理解すること
- 適正利用のための内部ルールを策定すること
- 従業員への著作権教育を実施すること
- 生成物が既存著作物に類似していないか確認する体制を整えること
- 生成過程を記録し、依拠性がないことを説明できる状態にすること
最新の法的動向とガイドラインの更新
文化庁のガイドラインは、技術の進展や社会の変化に応じて随時更新される可能性があります。企業は定期的に文化庁のウェブサイトをチェックし、最新の見解を把握しておく必要があります。
また、AI推進法の施行に伴い、今後さらに詳細な事業者向けガイドラインが整備される見込みです。経済産業省のAI事業者ガイドラインと合わせて確認し、コンプライアンス体制を継続的にアップデートしましょう。
文化庁の公式資料は以下から入手できます。
- 文化庁「AIと著作権」特設ページ
- 「AIと著作権に関する考え方について」PDF資料
- 令和5年度著作権セミナー資料
これらの資料を社内研修や勉強会で活用し、組織全体の理解を深めることが、安全な生成AI活用の基盤となります。
まとめ|生成AIと著作権の境界線を正しく理解しリスクを管理する
生成AIの著作権問題は、開発・学習段階と生成・利用段階で適用されるルールが根本的に異なります。
学習段階では著作権法第30条の4により非享受目的の利用として原則適法ですが、享受目的が併存する場合や権利者の利益を不当に害する場合は例外的に違法となります。
生成・利用段階では、AI生成物が既存の著作物と表現上の本質的な特徴において類似しており、かつ依拠性が認められる場合に著作権侵害が成立します。特に依拠性は、利用者が知らなくてもAIの学習データに含まれていた場合に推認される可能性があるため、企業は生成物のチェック体制を整備する必要があります。
AI生成物の著作権は原則として発生しませんが、人間による創作意図と創作的寄与が認められれば著作物として保護される可能性があります。試行錯誤や大幅な修正を加えることで、人間の創作性を付加することが重要です。
企業が安全に生成AIを活用するためには、権利関係がクリーンなツールの選定、社内ガイドラインの策定、プロンプト設計の工夫、類似性チェックの徹底、専門家によるリーガルチェック、利用規約の詳細確認、段階別チェックリストの運用、文化庁ガイドラインの継続的な確認といった多層的な対策が求められます。
生成AIは業務効率化や創造性向上に大きく貢献する技術ですが、法的リスクを正しく理解し適切に管理することで、企業の信頼を守りながら持続的にイノベーションを推進できます。著作権への配慮を怠らず、クリエイターの権利を尊重する姿勢を持ちながら、新しい技術を賢く活用していきましょう。

