
「AIって聞くけど、実際どういう仕組みなんだろう?」そんな疑問を抱く方が増えています。

ニュースでは毎日のように生成AIやChatGPTが話題になり、ビジネスの現場でも導入が進む中、AIの基本を理解しておくことは今や必須スキルといえるでしょう。
この記事では、AI・機械学習・ディープラーニングという3つの概念の違いから、最新のトランスフォーマーやLLMまで、専門用語をできるだけ避けながらわかりやすく解説します。
イラストや図解を交えながら、AIの歴史、仕組み、実用例、そして頻出用語まで網羅的にお伝えしますので、この記事を読めば、AIに関する会話にも自信を持って参加できるようになります。

AIとは何か|人間の知能を再現する技術の全体像
AI(Artificial Intelligence:人工知能)とは、人間の知的な活動、つまり学習・認識・理解・予測・推論・計画・最適化といった能力をコンピュータで実現する技術の総称です。もう少し具体的に言えば、人間が頭を使って判断したり、経験から学んだりする作業を、機械に代わりにやってもらおうという技術全般を指します。
実はAIに明確な統一定義は存在しません。研究者や企業によって解釈が異なり、「何をAIと呼ぶか」も時代とともに変化してきました。ただし、共通しているのは「人間の知能に近い働きを機械で再現する」という目標です。
AIの誕生と歴史的背景
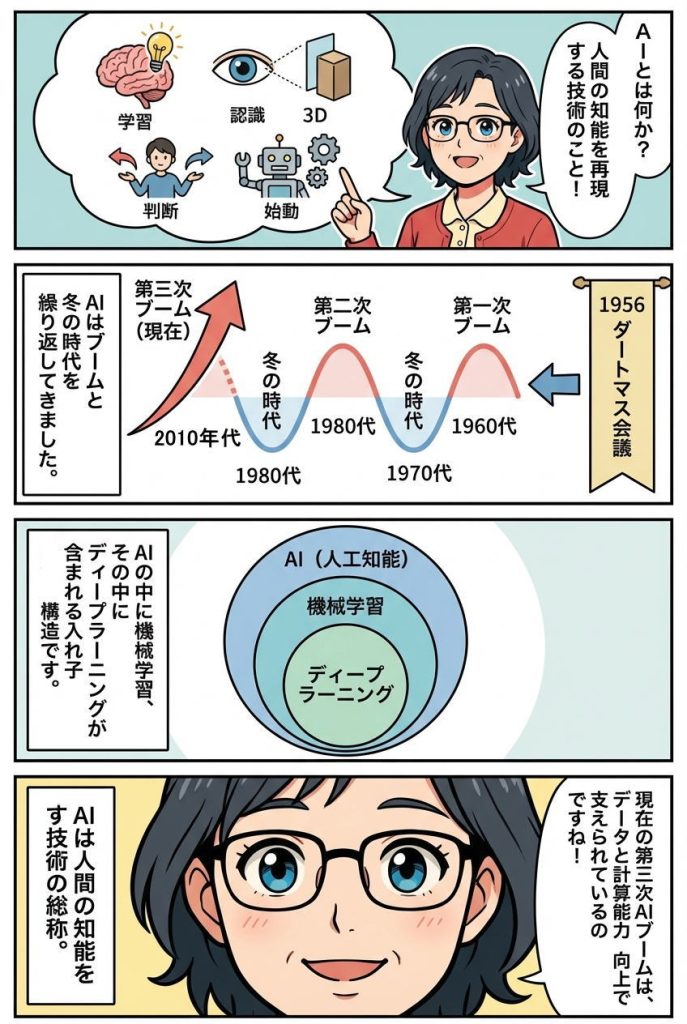
AIという概念が初めて提唱されたのは1956年のダートマス会議です。
当時のコンピュータ科学者たちは「人間のように考えるマシンを作れるのではないか」という夢を抱き、AI研究の分野を確立しました。
しかし、AIは順風満帆に進化してきたわけではありません。何度もブームと冬の時代を繰り返してきたのです。初期の1960年代から1970年代にかけて「第一次AIブーム」が訪れましたが、計算能力の限界や複雑な問題への対応の難しさから停滞期に入ります。1980年代には専門家の知識をルールとしてコンピュータに組み込む「エキスパートシステム」が登場し、「第二次AIブーム」が起こりましたが、ルールの設定や保守に膨大なコストがかかり、再び冬の時代を迎えました。
そして2010年代以降、私たちは「第三次AIブーム」の真っ只中にいます。この飛躍的な成長を支えているのが、コンピュータの処理能力の劇的な向上、大量データの蓄積、そして機械学習やディープラーニングといった革新的な技術です。
AI・機械学習・ディープラーニングの関係性
AIについて理解する上で重要なのが、AI・機械学習・ディープラーニングという3つの概念の関係性です。これらは同じものではなく、入れ子構造になっています。
最も大きな枠組みがAI(人工知能)です。その中に機械学習という手法が含まれ、さらに機械学習の中にディープラーニングという技術が含まれます。同心円状に広がっているイメージを持つと理解しやすいでしょう。
- AI(最も広い概念):人間の知能を再現する技術全般
- 機械学習(AIを実現する手法):データから自動的にパターンやルールを学ぶ技術
- ディープラーニング(機械学習の一種):脳の神経回路を模した多層構造で学習する技術
つまり、ディープラーニングは機械学習の一部であり、機械学習はAIを実現するための具体的なアプローチの一つなのです。
特化型AIと汎用AIの違い
AI研究の究極的な目標は「汎用AI」(General AI)の実現です。これは人間と同じようにあらゆる知的作業をこなせるAIで、映画「ターミネーター」や「スター・ウォーズのC-3PO」のように、自分で考え、判断し、学習できる存在を指します。
しかし現時点で実用化されているのは「特化型AI」(Narrow AI)と呼ばれるものです。特定の限られたタスクにおいて人間と同等、あるいはそれ以上の性能を発揮するAIです。顔認識システム、音声アシスタント、画像診断、囲碁や将棋のAIなどがこれに該当します。
汎用AIの実現はまだ遠い未来の話で、研究者の間でも「実現可能なのか」について意見が分かれています。現在、私たちが日常で触れているAIはすべて特化型AIであり、それぞれの得意分野で力を発揮しているのが実情です。
機械学習の定義と仕組み|データから自動的に学ぶ技術
機械学習(Machine Learning)とは、コンピュータが大量のデータを分析し、その中に潜むパターンや規則性を自動的に見つけ出す技術です。
従来のプログラミングでは、開発者があらかじめすべての動作をルールとして記述する必要がありましたが、機械学習ではデータさえ与えれば、コンピュータ自身が「どうすればうまくいくか」を学習できます。
機械学習の基本的な考え方
機械学習を理解する上で重要なのは「学習」という概念です。人間が経験から学ぶように、機械学習では過去のデータから学習し、未知のデータに対して予測や判断を行います。
たとえば、メールのスパムフィルターを考えてみましょう。過去に受信した何千通ものメールを「スパム」と「正常なメール」に分類したデータを用意します。機械学習アルゴリズムはこのデータを分析し、「スパムメールにはこういう特徴がある」というパターンを自動的に見つけ出します。その結果、新しく届いたメールについても、学習したパターンに基づいて「これはスパムである可能性が高い」と判断できるようになるのです。
この仕組みの優れた点は、明示的に「この単語が含まれていたらスパム」というルールを人間が設定しなくても、データさえあればコンピュータが自動的に特徴を見つけてくれることです。
機械学習における特徴量の役割
ただし、従来の機械学習では人間が「どのデータに注目すべきか」を事前に決める必要がありました。これを「特徴量の設計」と呼びます。
売上予測を例にとると、曜日によって売上が変動するなら「曜日情報」を特徴量として設定します。天気の影響があるなら「天候データ」も加えます。こうした特徴量の選択と設計は、機械学習の精度を大きく左右する重要な作業でした。
この「人間が特徴量を設計する」という制約が、ディープラーニングの登場によって大きく変わることになります。
機械学習の3つの種類|教師あり・教師なし・強化学習
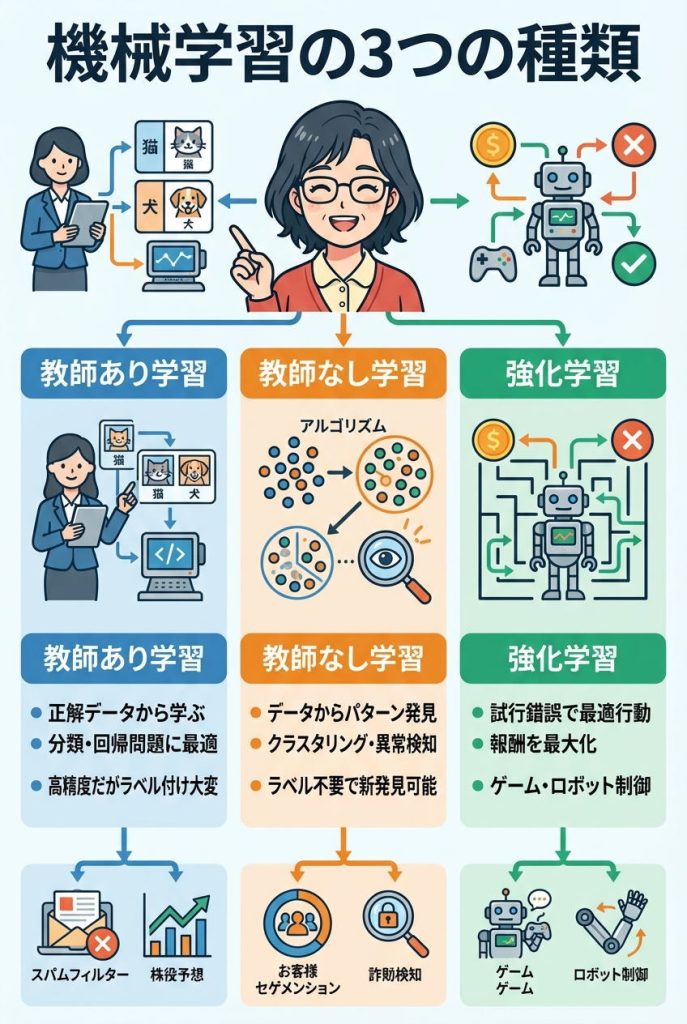
機械学習は学習の方法によって、主に3つのタイプに分類されます。それぞれ異なる目的と得意分野を持っているため、課題に応じて使い分けることが重要です。
教師あり学習|正解データから学ぶ手法
教師あり学習(Supervised Learning)は、「正解ラベル」が付いたデータを使って学習する方法です。教師が生徒に正解を教えるように、コンピュータに「これが正解」というデータを大量に与えて学習させます。
具体的には、画像認識で「この画像は猫」「この画像は犬」というラベル付きのデータを何千枚も用意し、それを学習させることで、新しい画像に対しても「これは猫である確率90パーセント」といった予測ができるようになります。
教師あり学習は以下のようなタスクに適しています。
- 分類問題:メールのスパム判定、病気の診断、商品のカテゴリ分け
- 回帰問題:株価予測、気温予測、住宅価格の推定
メリットは精度の高い予測ができることですが、デメリットとしては正解ラベルを付ける作業に膨大な時間とコストがかかる点が挙げられます。何万枚もの画像に手作業でラベルを付けるのは大変な労力です。
教師なし学習|データの構造を見つける手法
教師なし学習(Unsupervised Learning)は、正解ラベルがないデータから自動的にパターンや構造を見つけ出す方法です。データの特徴に基づいて自動的にグループ分けしたり、データの背後にある構造を明らかにしたりします。
代表的な手法に「クラスタリング」があります。たとえば、ECサイトの顧客データを分析する際、購買履歴や閲覧履歴から似た行動パターンを持つ顧客をグループ化します。人間が事前に「こういうグループに分けなさい」と指示しなくても、アルゴリズムが自動的に「高頻度購入者グループ」「閲覧のみで購入しない層」などを発見してくれるのです。
教師なし学習の活用例としては以下が挙げられます。
- 顧客セグメンテーション
- 異常検知(不正取引の発見)
- レコメンデーションシステム
- データの次元削減(複雑なデータの可視化)
教師なし学習のメリットは、ラベル付けが不要なためコストが低く、人間が気づかなかった新しいパターンを発見できる点です。
強化学習|試行錯誤で最適な行動を学ぶ手法
強化学習(Reinforcement Learning)は、試行錯誤を通じて最適な行動を学習する方法です。ゲームをクリアするために何度も挑戦して上達していく過程に似ています。
強化学習では、AIエージェントが環境の中で行動し、その結果として「報酬」または「ペナルティ」を受け取ります。報酬を最大化するように行動を調整していくことで、最終的に最適な戦略を獲得します。
代表的な成功例が、AlphaGoです。Googleの子会社DeepMindが開発したAlphaGoは、強化学習を使って自分自身と何百万回も対局を繰り返し、人間のプロ棋士を超える実力を獲得しました。
強化学習の応用例は多岐にわたります。
- ゲームAI
- ロボット制御
- 自動運転
- 在庫管理や配送ルートの最適化
強化学習は、正解データがなく、試行錯誤を通じて最適解を探す必要がある問題に特に有効です。
ディープラーニングの定義と仕組み|機械学習の革新
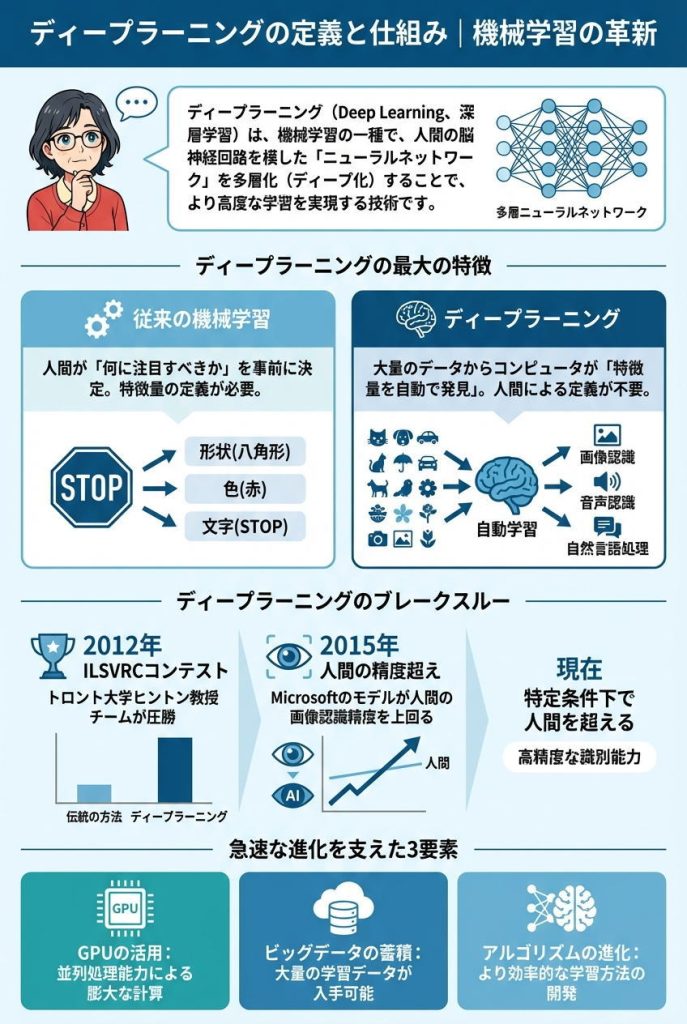
ディープラーニング(Deep Learning、深層学習)は、機械学習の一種で、人間の脳神経回路を模した「ニューラルネットワーク」を多層化(ディープ化)することで、より高度な学習を実現する技術です。
ディープラーニングの最大の特徴
ディープラーニングが従来の機械学習と決定的に違うのは、「特徴量を自動で発見できる」という点です。
従来の機械学習では、人間が「何に注目すべきか」を事前に決める必要がありました。たとえば一時停止の道路標識を認識させるには、「八角形の形状」「赤い色」「STOPという文字」といった特徴を人間が定義し、それぞれを判定するプログラムを個別に作成する必要がありました。
しかしディープラーニングでは、大量の画像データを与えるだけで、コンピュータ自身が「一時停止標識にはこういう特徴がある」というパターンを自動的に学習します。人間が「この特徴に注目しなさい」と指示する必要がないのです。
この革新により、画像認識、音声認識、自然言語処理など、従来は人間にしかできないと思われていた複雑なタスクで、人間を超える精度を達成できるようになりました。
ディープラーニングのブレークスルー
ディープラーニングが注目を集めるきっかけとなったのは、2012年の画像認識コンテスト「ILSVRC」でした。トロント大学のジェフリー・ヒントン教授のチームが開発したディープラーニングモデルが、従来手法を大きく引き離して優勝したのです。
その後も研究は加速し、2015年にはMicrosoftのディープラーニングモデルが人間の画像認識精度を超えました。現在では、特定の条件下において、AIは人間よりも高精度で画像を識別できるようになっています。
こうした急速な進化を支えたのが、以下の3つの要素です。
- GPU(画像処理プロセッサ)の活用:並列処理能力に優れたGPUにより、膨大な計算が可能に
- ビッグデータの蓄積:インターネットの普及により、学習に必要な大量データが入手可能に
- アルゴリズムの進化:より効率的な学習方法が次々と開発された
ニューラルネットワーク入門|脳を模した学習の仕組み
ニューラルネットワーク(Neural Network)は、人間の脳の神経細胞(ニューロン)の働きを数理モデル化した仕組みです。ディープラーニングの基礎となる技術で、この構造を理解することでAIの学習メカニズムが見えてきます。
ニューラルネットワークの基本構造
ニューラルネットワークは、複数の層(レイヤー)から構成されています。基本的には3つの層があります。
- 入力層:データを受け取る層
- 中間層(隠れ層):実際の計算や判断を行う層
- 出力層:最終的な結果を出力する層
たとえば手書き数字認識を考えてみましょう。入力層には画像のピクセル情報が入ります。中間層では各ピクセルの特徴(線の角度、曲がり具合など)が解析され、出力層で「この数字は7である確率が95パーセント」といった結果が出力されます。
ニューロン同士の情報伝達
各層のニューロン(計算単位)は、前の層から情報を受け取り、重み付けして次の層に渡します。この「重み」こそが学習の核心です。
最初はランダムな重みから始まりますが、正解データと照らし合わせて誤差を計算し、その誤差が小さくなるように重みを少しずつ調整していきます。このプロセスを何千回、何万回と繰り返すことで、ネットワークは正確な予測ができるようになっていくのです。
多層化がもたらす表現力
ディープラーニングの「ディープ」は、この中間層を4層以上に深くすることを意味します。層が深いほど、より抽象的で複雑なパターンを学習できるようになります。
画像認識を例にとると、初期の層では「エッジ(輪郭)」といった単純な特徴を捉えます。次の層ではそれらを組み合わせて「目」や「耳」といったパーツを認識し、さらに深い層で「顔全体」を認識する、といった階層的な学習が行われます。
この多層構造により、人間の脳が段階的に情報処理するのと似たプロセスが実現されているのです。
トランスフォーマーアーキテクチャ|自然言語処理の革命
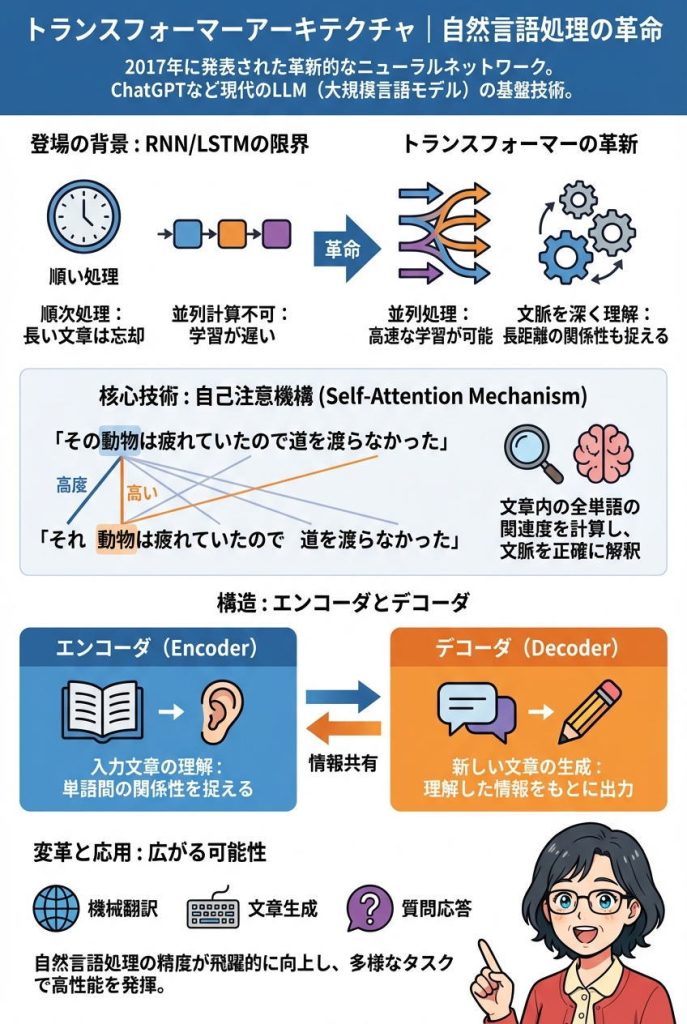
トランスフォーマー(Transformer)は、2017年に発表された革新的なニューラルネットワークのアーキテクチャで、自然言語処理の分野に革命をもたらしました。ChatGPTをはじめとする現代のLLM(大規模言語モデル)の基盤技術となっています。
トランスフォーマー登場の背景
トランスフォーマー以前の自然言語処理では、RNN(再帰型ニューラルネットワーク)やLSTMといった技術が主流でした。これらは文章を頭から順番に処理していく仕組みでしたが、長い文章になると初めの方の情報を忘れてしまう問題がありました。
また、順番に処理するため並列計算ができず、学習に膨大な時間がかかるという課題も抱えていました。
自己注意機構という革新
トランスフォーマーの核心技術が「自己注意機構」(Self-Attention Mechanism)です。これは文章内のすべての単語が、他のすべての単語とどれくらい関連しているかを計算する仕組みです。
たとえば「その動物は疲れていたので道を渡らなかった」という文で、「それ」が何を指すかを判断する必要があるとします。人間は文脈から「それ」が「動物」を指すと理解しますが、機械にとってこの判断は難しい作業でした。
自己注意機構では、「それ」という単語が文章内の他の単語(動物、疲れていた、道など)とどれだけ関連があるかをスコア化します。その結果、「それ」は「動物」と強く関連していることが数値で表され、正確な解釈が可能になります。
エンコーダとデコーダの役割
トランスフォーマーは「エンコーダ」と「デコーダ」という2つの主要部分で構成されます。
エンコーダは入力された文章を理解する役割を担います。自己注意機構を使って文章内の単語間の関係性を捉え、文脈を深く理解します。
デコーダはエンコーダが理解した情報をもとに、新しい文章を生成します。翻訳であれば、日本語を理解したエンコーダの情報を受けて、デコーダが英語の文章を生成するイメージです。
この組み合わせにより、トランスフォーマーは機械翻訳、文章生成、質問応答など、さまざまな自然言語処理タスクで高い性能を発揮できるようになりました。
トランスフォーマーがもたらした変革
トランスフォーマーの登場により、自然言語処理の精度が飛躍的に向上しただけでなく、学習速度も大幅に改善されました。並列計算が可能になったため、GPUを活用して効率的に学習できるようになったのです。
この技術革新が、後述するGPTやBERTといった大規模言語モデルの開発につながり、現在の生成AIブームの基礎を築きました。
LLM(大規模言語モデル)解説|ChatGPTを支える技術
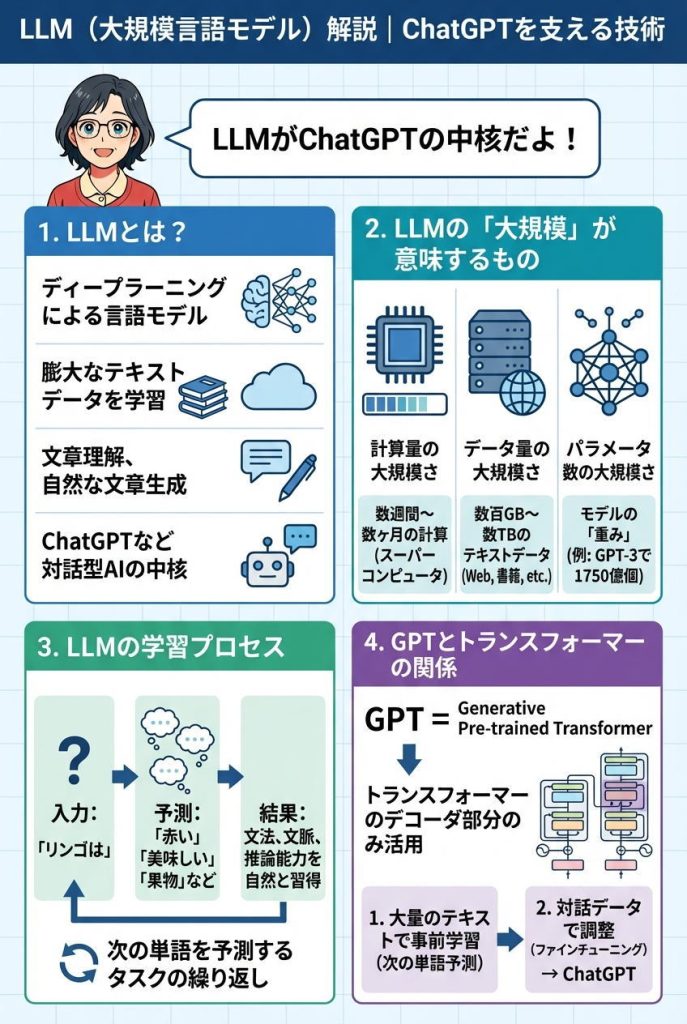
LLM(Large Language Model:大規模言語モデル)とは、膨大なテキストデータとディープラーニング技術によって構築された言語モデルです。文章を理解し、自然な文章を生成できる能力を持ち、ChatGPTをはじめとする対話型AIの中核を担っています。
LLMの「大規模」が意味するもの
LLMの「大規模」には3つの意味があります。
まず計算量の大規模さです。LLMの学習には、数週間から数ヶ月にわたる膨大な計算が必要で、1秒間に1000兆回以上の計算を行うスーパーコンピュータが使われます。
次にデータ量の大規模さです。LLMは数百ギガバイトから数テラバイトにおよぶテキストデータで学習します。書籍、ニュース記事、ウェブページ、SNSの投稿など、インターネット上のあらゆる文章が学習データとなります。
最後にパラメータ数の大規模さです。パラメータとは、モデルが学習によって調整する「重み」のことで、この数が多いほど複雑な言語パターンを学習できます。GPT-3は1750億個のパラメータを持ち、GPT-4ではさらに増加していると言われています。
LLMの学習プロセス
LLMは主に「次の単語を予測する」というシンプルなタスクで訓練されます。たとえば「リンゴは」という入力に対して、「赤い」「美味しい」「果物」など、次に続く可能性の高い単語を予測します。
この訓練を膨大なテキストデータで繰り返すことで、LLMは文法、文脈、知識、さらには推論能力まで獲得していきます。驚くべきことに、明示的に教えなくても、大量のテキストから自然とこれらの能力が身につくのです。
学習後のLLMは、質問応答、文章生成、要約、翻訳、コード作成など、さまざまな言語タスクをこなせるようになります。
GPTとトランスフォーマーの関係
ChatGPTの「GPT」は「Generative Pre-trained Transformer」の略で、「生成的な事前学習済みトランスフォーマー」という意味です。
GPTは、トランスフォーマーのデコーダ部分のみを活用したアーキテクチャです。大量のテキストデータで事前学習を行い、次の単語を予測する能力を磨きます。その後、対話データでさらに調整(ファインチューニング)することで、ChatGPTのような対話型AIとして機能するようになります。
LLMの応用と可能性
LLMは以下のような幅広い分野で活用されています。
- 対話型アシスタント:ChatGPT、Bard、Claudeなど
- 文章作成支援:メール作成、レポート執筆、クリエイティブライティング
- コード生成:GitHub Copilot、プログラミング支援
- 教育:個別指導、学習サポート
- カスタマーサポート:自動応答、問い合わせ対応
- 翻訳・要約:多言語対応、情報抽出
LLMは単なる文章生成ツールではなく、知識の検索、推論、問題解決まで幅広い知的作業を支援できる可能性を秘めています。
LLMの課題と注意点
LLMは強力な技術ですが、いくつかの課題も抱えています。
- ハルシネーション(幻覚):もっともらしいが事実でない情報を生成してしまうことがある
- バイアスの問題:学習データに含まれる偏見を反映してしまう可能性
- 情報の鮮度:学習データの時点までの情報しか持たない
- 環境負荷:学習に膨大な電力を消費する
これらの課題に対しては、RAG(検索拡張生成)による情報補強、人間によるフィードバック学習、軽量化技術の開発など、さまざまな改善策が研究されています。
頻出用語集50選|AI・機械学習・ディープラーニング
AI関連の記事や会話でよく登場する重要用語を、カテゴリ別に解説します。
AI基礎用語
アルゴリズム:問題を解決するための手順や計算方法。AIではデータ処理の方法を指す
データセット:機械学習の訓練や評価に使用するデータの集まり
学習:データからパターンを見つけ出し、予測や判断の精度を向上させるプロセス
推論:学習済みモデルを使って、新しいデータに対する予測や判断を行うこと
汎化:学習データだけでなく、未知のデータに対しても正確に予測できる能力
過学習:学習データには完璧に対応できるが、新しいデータでは性能が落ちる状態
ハイパーパラメータ:学習前に人間が設定する調整値。学習率、層の数など
機械学習関連用語
訓練データ:モデルの学習に使用するデータセット
テストデータ:学習後のモデルの性能を評価するためのデータ
検証データ:モデルの調整や選択に使用する、訓練とは別のデータ
分類:データをカテゴリに分ける問題。スパム判定、画像分類など
回帰:連続的な数値を予測する問題。売上予測、気温予測など
クラスタリング:似たデータをグループ分けする教師なし学習の手法
次元削減:複雑なデータをより少ない特徴で表現する技術
決定木:木構造でデータを分岐させて予測を行う手法
ランダムフォレスト:複数の決定木を組み合わせて予測精度を向上させる手法
勾配ブースティング:弱い予測モデルを順次改善していく手法
ディープラーニング関連用語
活性化関数:ニューロンの出力を決定する関数。ReLU、Sigmoidなど
バックプロパゲーション:誤差を逆方向に伝播させて重みを調整する学習方法
エポック:全訓練データを一通り学習すること。複数回繰り返す
バッチサイズ:一度に処理するデータのまとまりの大きさ
学習率:パラメータの更新幅を決める値。大きすぎると不安定に
損失関数:予測と正解の誤差を数値化する関数
最適化:損失を最小化するようパラメータを調整すること
ドロップアウト:過学習を防ぐため、ランダムにニューロンを無効化する手法
正規化:データのスケールを揃えて学習を安定させる処理
バッチ正規化:層ごとに出力を正規化して学習を高速化する技術
ニューラルネットワーク種類
CNN(畳み込みニューラルネットワーク):画像認識に特化したネットワーク構造
RNN(再帰型ニューラルネットワーク):時系列データや文章処理に適した構造
LSTM(長短期記憶):長期的な依存関係を学習できるRNNの改良版
GAN(敵対的生成ネットワーク):生成器と識別器を競わせて高品質データを生成
VAE(変分オートエンコーダ):データの特徴を圧縮・生成できるモデル
自然言語処理用語
トークン:文章を分割した最小単位。単語や文字など
エンベディング:単語を数値ベクトルに変換する技術
注意機構:文章内の重要な部分に注目する仕組み
BERT:双方向に文脈を理解できる言語モデル
ファインチューニング:事前学習済みモデルを特定タスク向けに調整すること
プロンプト:AIに対する指示や質問文
コンテキスト:文脈、前後の情報
セマンティック検索:意味を理解して検索する技術
生成AI関連用語
生成AI:テキスト、画像、音声などを生成できるAI
マルチモーダル:テキスト、画像、音声など複数のデータ形式を扱える能力
プロンプトエンジニアリング:AIから望ましい出力を得るための指示の工夫
Zero-shot学習:事例なしでタスクを実行できる能力
Few-shot学習:少数の事例から学習して新しいタスクに対応する能力
RAG(検索拡張生成):外部知識を検索して回答の精度を向上させる手法
ハルシネーション:AIが事実でない情報をもっともらしく生成してしまうこと
モデレーション:不適切なコンテンツを検出・制御する機能
技術・環境用語
GPU:並列計算に優れたプロセッサ。AI学習の高速化に不可欠
クラウドAI:クラウド上で提供されるAIサービス
エッジAI:デバイス上で動作する軽量なAI
転移学習:別タスクで学習したモデルを活用する手法
アンサンブル学習:複数モデルを組み合わせて精度を向上させる手法
これらの用語を理解することで、AI関連の記事やニュースがより理解しやすくなります。
AIの歴史と発展|3度のブームと技術革新
AI技術は一直線に進化してきたわけではなく、期待と失望を繰り返しながら発展してきました。その歴史を知ることで、現在のAIブームがどれほど特別なものかが理解できます。
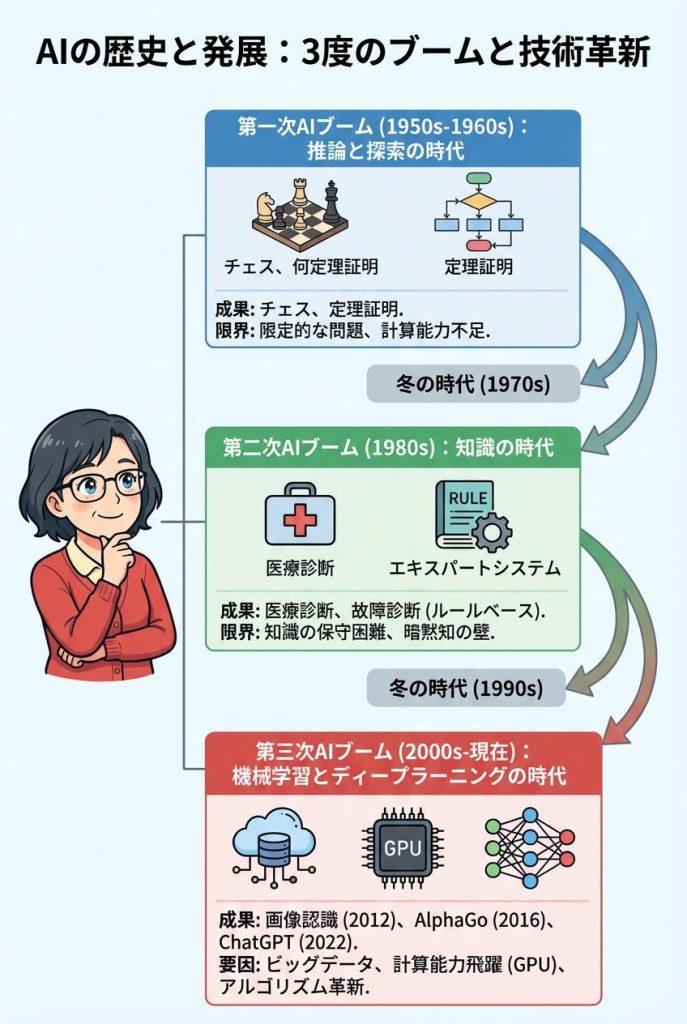
第一次AIブーム|推論と探索の時代
1956年のダートマス会議でAIという分野が誕生してから、1960年代にかけてが第一次AIブームです。この時期、研究者たちは「コンピュータで人間のように考えることができる」という楽観的な期待を抱いていました。
代表的な成果としては、チェスプログラムや定理証明プログラムが開発されました。しかし、これらは限定的な問題しか解けず、現実世界の複雑な問題には対応できませんでした。コンピュータの計算能力不足や、知識の表現方法の難しさが壁となり、1970年代には第一次AI冬の時代を迎えます。
第二次AIブーム|知識の時代
1980年代に訪れた第二次AIブームは「エキスパートシステム」の登場によって始まりました。専門家の知識をルールとしてコンピュータに記述することで、医療診断や故障診断などの実用的なシステムが開発されました。
日本でも通産省(現経済産業省)主導の「第五世代コンピュータプロジェクト」が進められ、AI研究に国家レベルで投資が行われました。
しかし、知識をすべてルール化するには膨大な労力が必要で、知識の保守更新も困難でした。さらに、専門家自身が説明できない「暗黙知」をルール化することは不可能に近く、実用化の壁に直面しました。1990年代には再び冬の時代が訪れます。
第三次AIブーム|機械学習とディープラーニングの時代
2000年代以降、機械学習の実用化が進み、2010年代にディープラーニングが登場したことで、第三次AIブームが到来しました。このブームは過去のものとは質的に異なり、実際に社会を変える力を持っています。
2012年の画像認識コンテストでの圧勝、2016年のAlphaGoによる囲碁世界王者への勝利、そして2022年のChatGPT登場と、立て続けに画期的な成果が生まれています。
このブームを支える3つの要因があります。
- ビッグデータの時代:インターネットとスマートフォンの普及で膨大なデータが蓄積
- 計算能力の飛躍:GPUの活用により並列計算が可能に
- アルゴリズムの革新:ディープラーニング、トランスフォーマーなど効率的な手法の開発
現在のAIは実際に経済価値を生み出し、産業構造を変えつつあります。過去のブームとは異なり、この流れは長期的に続くと予想されています。
まとめ|AI技術の全体像と今後の展望
この記事では、AIの基礎から最新のLLMまで、包括的に解説してきました。
AIは人間の知能を再現する技術全般を指し、その中に機械学習という手法があり、さらに機械学習の中にディープラーニングという技術があるという入れ子構造になっています。機械学習には教師あり学習、教師なし学習、強化学習という3つの主要な学習方法があり、それぞれ異なる問題に適しています。
ディープラーニングは脳の神経回路を模したニューラルネットワークを多層化することで、人間が特徴を指定しなくてもデータから自動的にパターンを学習できる画期的な技術です。そしてトランスフォーマーという革新的なアーキテクチャの登場により、自然言語処理の精度が飛躍的に向上し、ChatGPTをはじめとするLLMが実現しました。
AI技術は過去に2度のブームと冬の時代を経験しましたが、現在の第三次AIブームは実社会に大きな影響を与えており、その勢いは今後も続くと予想されます。ただし、ハルシネーション、バイアス、環境負荷といった課題も存在し、技術の進化と同時に倫理的な配慮や社会的な議論も重要になってきています。
AIは決して遠い未来の技術ではなく、すでに私たちの日常に深く浸透しています。スマートフォンの音声アシスタント、動画配信サービスのレコメンデーション、メールのスパムフィルター、カメラの顔認識など、意識しないうちに多くのAI技術を利用しているのです。
今後、AIは医療、教育、製造、交通、金融など、あらゆる分野でさらに活用が進むでしょう。AI技術の基本を理解しておくことは、これからの時代を生きる上で欠かせないリテラシーとなります。この記事がその第一歩となれば幸いです。

